Intercompany Eliminations in PBCS
As part of a recent PBCS implementation, I had to design an Intercompany Elimination solution within a BSO plan type. This is a relatively uncommon and somewhat complex requirement in a PBCS implementation, and as such, I was pretty excited to blog about it. Unfortunately, the whole post nearly ended up in the garbage.
Every once in a while, you write a great post, only to find that someone else has covered the topic sooner than you, and better than you. In my case, that person was Martin Neuliep. In Developing Essbase Applications: Hybrid Techniques and Practices, Martin shared a single formula that elegantly calculated Intercompany Eliminations in a BSO cube. In addition, Martin was scheduled to discuss the topic of eliminations at Kscope in his presentation on June 28th, titled Eliminating the Eliminations Problem in Essbase.
Luckily, I had an ASO solution in addition to my BSO approach. As it turns out, Martin was planning on sharing several elimination calculation methods in his presentation (some developed by him, and some developed by others). Perhaps my ASO solution will make the cut? (hint, hint) Either way, you should check out his presentation – I will definitely be there.
With all of that said, here’s my approach to intercompany eliminations in an ASO plan type.
Why Eliminate Intercompany Transactions?
Most of my clients create their Budgets and Forecasts in a “fully eliminated” manner. Within their financial plans, they pretend that certain transactions don’t occur, because these transactions don’t affect the company’s bottom line. If one subsidiary has a planned (future) transaction with another subsidiary, these clients may not bother recording the transaction in their Budget or Forecast at all. While this approach simplifies the planning process, it leaves out financial details that may be useful.
When a client’s requirements indicate that these transactions are relevant to the planning process, we need to build Intercompany Elimination logic into our PBCS applications. The accounting behind these transactions can get pretty complex, but what we’re going to focus on today are the technical mechanics that facilitate these eliminations in PBCS, specifically in an ASO plan type.
So why do we eliminate these transactions? Because depending on where we’re looking in the Entity dimension, we need to pretend that they never occurred. As far as most investors are concerned, these intercompany transactions don’t count on a consolidated basis. Imagine selling a car to your spouse . . . this transaction doesn’t change your combined income or net worth. This leads us to an interesting question. When and where do we eliminate these transactions?
The Land of Make Believe
Let’s start with a simple example – an imaginary company that mines raw materials and sells those materials to its manufacturing units. These plants then sell finished goods to a distribution company. All of these entities are part of the same vertically integrated company. The Entity dimension in such a company might looks like this:
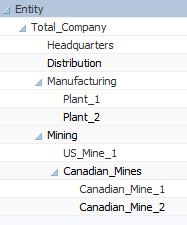
To facilitate transactions between two entities in an OLAP database, it is generally beneficial to have separate Entity and Customer Dimensions. The only unusual thing about this design is that many of the “Customers” are internal customers. As such, our Customer dimension might look something like this:
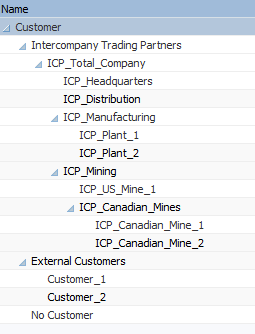
Note that all members under Intercompany Trading Partners correspond with a member from the Entity dimension exactly, but with an “ICP_” prefix. This ASO solution will not work if there are discrepancies between Entity dimension members and the members underneath Intercompany Trading Partners.
Planning Intercompany Transactions
Intercompany transactions can occur across a variety of accounts within the Income Statement and Balance Sheet. The simplest example is one subsidiary selling something to another subsidiary within the same company. Let’s assume that US Mine 1 sells something to Plant 1 for $100. Our level zero data would look something like this in PBCS:

If we were to look at Total Sales for US_Mine_1, we would want to see $100 in sales. But what if we wanted to see Total Sales for Total_Company? Assuming that this was the only sale, we would want to see $0. This is because the transaction must be eliminated at the first common ancestor between the Entity and the Intercompany Trading Partner. Total_Company is the first common ancestor between US_Mine_1 and Plant_1. What makes this calculation interesting is that the transaction should NOT be eliminated at ancestors before we arrive at the first common ancestor. So we would definitely expect to see that $100 in sales to show up in the parent member Mining.
The Dreaded “E-Company”
The ins-and-outs of these transactions can get tricky, especially when mixing many transactions together with both internal and external customers. Developers will likely have multiple sets of accounts being eliminated. (E.g., Sales & Cost of Sales, Receivables & Payables, etc.) Ragged hierarchies and alternate hierarchies can add additional complexity. For this reason, it can be helpful to introduce “E-Companies” into the Entity dimension. These are basically fake companies where we only calculate and store elimination data.
Adding E-Companies to the Entity dimension might look something like this:
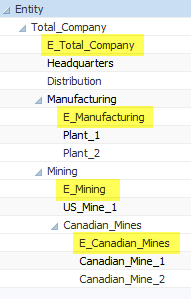
Unfortunately, E-Companies can make an Entity dimension convoluted. If your company structure is particularly large or volatile, E-Companies can create a significant amount of maintenance. They can also be confusing to end-users who might not understand their purpose.
** NOTE – Most intercompany elimination solutions in BSO databases require E-Companies!
ASO to the Rescue!
One of the nice things about PBCS implementations is that they often include an ASO reporting database. In fact, some clients never consolidate their BSO databases at all, and instead, simply map their data to an ASO cube that rolls everything up on the fly – no business rule required! And here’s where things get really awesome – in an ASO database, we can calculate intercompany eliminations without the need for E-Companies.
Here are some things to consider when designing your ASO plan type:
- Both an Entity dimension and a Customer dimension are required.
- The Intercompany Trading Partner hierarchy (within the Customer dimension) must match the Entity dimension exactly, with the exception of “ICP_” prefixes. This includes intermediate parents.
- A “Data Source” dimension of some type is required to separate regular data from eliminations.
- Account dimensions in ASO databases are automatically set to Dynamic. The Data Source dimension will also need to be dynamic to support member formulas.
The Data Source Dimension
In this solution, all of the logic associated with eliminations lives in a dimension called Data Source (or something similar). In this dimension, all base (non-eliminated) data is loaded into a member called Amount.
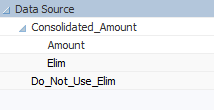
This dimension also includes a special “Do Not Use” system-only type of member. Here, it is called Do_Not_Use_Elim. We generally do not want users querying this member. It’s just a temporary holding spot for storing the inverse balance for any intercompany accounts. This member can be populated with a procedural calculation.

It is important to note that the “Do Not Use” member should be populated in the same member combinations as the original budgeted amount, with the exception of the Data Source dimension. Remember – this “Do Not Use” member is simply a holding spot. Users should not query this member.
Abracadabra
The “real” magic happens in the member above called Elim. In this member, a formula is added that filters when eliminations (stored in the “Do Not Use” member) are displayed and subsequently added to the base data.

When the Elim member above rolls up to the Consolidated_Amount member, we see that the intercompany sales amount goes to zero. In other words, it is eliminated. (See row 15 below)
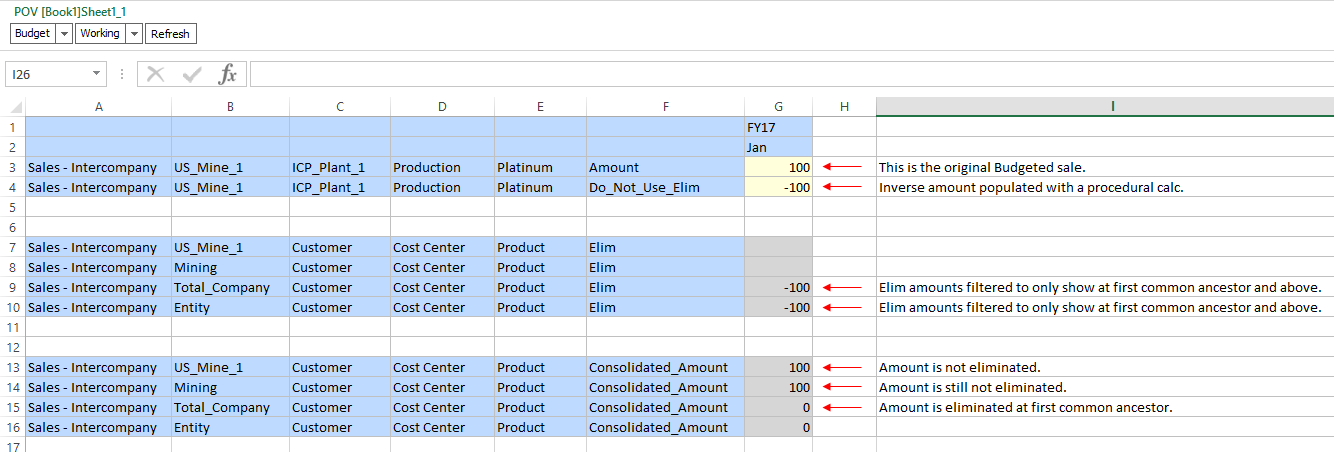
The example above shows our original sale (row 3) and the inverse amount stored in the “Do Not Use” member (row 4). Rows 7-10 show our original Entity and its ancestors. We can see that the eliminations are only displayed at the first common ancestor and above (row 9 – 10). Finally, in rows 13 – 16, we see the view that most users will retrieve, using the member Consolidated_Amount. This member takes the base data in the Amount member and layers in the data in the Elim member. As such, we can see that the sale exists in rows 13 & 14, but is eliminated in rows 15 and above.
Wrap-Up
Like most calculations in PBCS (and Essbase in general), there are multiple options for solutions, each with its own pro’s and con’s. This solution works well against very large databases and has the added benefit of not requiring E-Companies. Happy Eliminating!